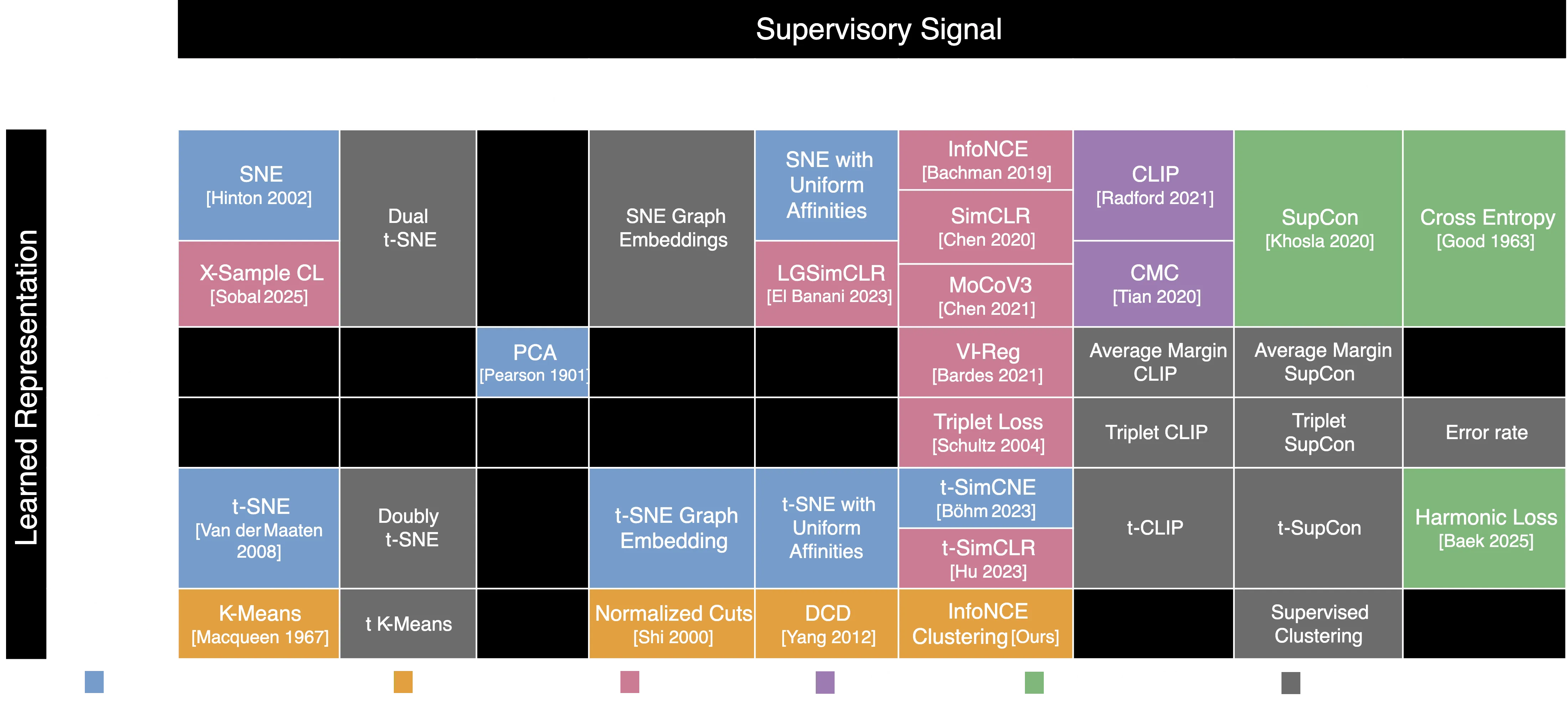
The Periodic Table of Representational Learning
Representational learning have been around for decades, and many techniques have been developed, to make sense of high-dimensional and frequently unlabelled data. However, the field has often been fragmented, with various methods appearing to be unrelated or even contradictory. This has made it difficult for researchers and practitioners to select the most suitable algorithm for their needs.
Researchers from Google, Microsoft, and MIT (an unusual collaboration) have discovered that numerous machine learning techniques, including seemingly unrelated methods such as t-SNE, PCA, CLIP, and triplet loss, can be understood as specific instances of a unified theoretical framework, they call I-CON. This effectively creates a “periodic table” for representation learning, offering a structured perspective on the relationships between these diverse approaches.
Having a look at the original paper is highly recommended. The section “HOW TO CHOOSE NEIGHBORHOOD DISTRIBUTIONS FOR YOUR PROBLEM” is particularly interesting, as it provides a practical guide for selecting the most appropriate algorithm for the specific use case.